
Artificial Intelligence (AI) technologies have started becoming larger parts of data center (DC) workloads, and the global DC community is challenged to make existing and new facilities AI-ready. Before the DC operation team decides on a range of actions, it is crucial to understand what AI is about, the type of expected IT workloads, and the immediate and future market needs.
The key steps are evaluating infrastructure components like power, cooling, network capacity, space utilization, and structural elements and proposing technical solutions. After analyzing all the above subjects, technical proposals, and points for further investigation, important conclusions and recommendations are presented here.
Artificial Intelligence (AI) is the theory and development of computer systems’ capability to perceive their environment, reason about their status, and select actions to perform certain tasks, in a similar way humans recognize visual or logical patterns, understand natural language, make decisions, and select actions accordingly.
Like humans, any AI system can develop intelligence based on experience and learning. This procedure is widely known as AI model training, where algorithms are fed massive data sets and trained to identify patterns, create experience, and develop non-linear models that relate the input data patterns to output predictions. AI is a general term that encompasses several technologies like machine learning (ML), deep learning (DL), and natural language processing (NLP), all of which use the same workflow to produce models.
Today, AI is not just a theoretical concept but a wide range of technologies that power services and products we use daily. Applications like face recognition, online recommendation systems, and real-time communication chatbots are tangible examples of AI systems trained on massive amounts of data to identify face characteristics, gender, age, or tokens of word sequences, create meaning, and respond verbally or by text.

The measurement in kW/GW indicates the overall computing resources available at the data center for data processing. As compute resources are servers equipped with CPUs and GPUs, these modules define the maximum available IT workload of the data center.
The number of processing and storage equipment stacks within racks defines rack density, measured in kW per rack. The more intensive and demanding the data stored, recalled, and processed, the more powerful CPUs and GPUs are required, and the rack density increases.
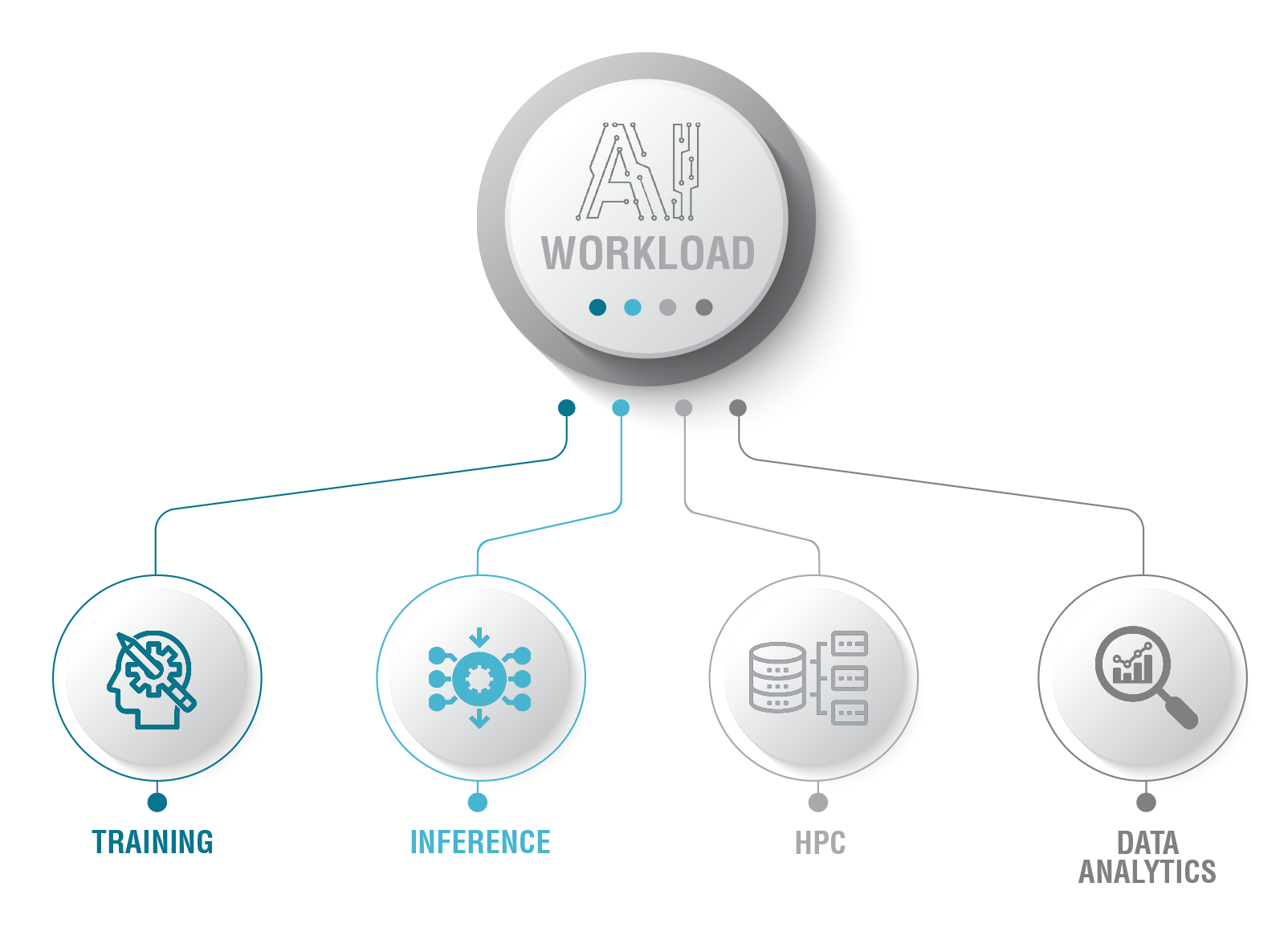
AI activity mainly includes leveraging various sizes of data sets and data streams through the data center’s computational resources. By performing storage, processing and modeling, the AI workload is:
a) Defined in terms of various data processing procedures like training, inference, data analytics and high-performance computing (HPC).
b) Quantified through the required IT computing power (kW) needed to implement.
The AI workload types managed by a data center facility are the following:
Training of new AI algorithms that utilize large to massive data sets and create neural networks with millions or billions of parameters. Popular machine learning tools create algorithms that go through extended calculations and iterations to adjust the model parameters and fit the algorithm onto the provided data set-specific patterns and behaviors.
After training completion, the outcome is called an AI model, which, under certain conditions, is ready for testing and deployment to production (e.g., large language models (LLMs) like ChatGPT already publicly available). Training various scales of AI models is expected to be the most demanding and computing power-intensive operation for future data centers.
Real-time inference is the procedure for deploying an AI model to production. In this case, the trained and tested AI model can receive new input data, provide predictions, generate results, and interact with the end user. Our daily interaction with AI applications like voice assistants, platform recommendation systems, weather forecasting, and email or bank fraud detection systems indicates the importance and massiveness of such developments. Thousands or millions of users simultaneously use a single or combination of models.
In the back scene, there is a continuous recall of AI models running in the DC facilities. Obviously, the more AI services penetrate new markets, the more models are created, and the more demand for real-time deep learning inference will occur in existing and future data centers.

HPC is an area of application mostly related to high-end research and academic applications where either traditional analytical approaches or AI based algorithms leverage large data sets and perform precise and floating-point demanding calculations to solve a problem.
In this case, again, the data center infrastructure operator will have to provide stacks of GPUs arranged into high-intensity racks and clusters, which become power-demanding and heat-generative. Recent advancements in medical research with DNA sequence alignment and protein structure prediction indicatively formalize the application of HPC and consequent data center infrastructure requirements.
Data Analytics is the phase that consumes most of the time in AI training workloads as it is related to massive data sets scraping, grouping, labeling, and creating pipe-flows for further processing and AI algorithms feed. The size of data sets is defined by the size and type of data. like photos or videos can create extended amounts of inputs to be stored and managed. This way, again, the data center workload increases significantly, requiring high-intensity IT equipment.
Data center infrastructure readiness for AI integration requires a thorough understanding of AI workloads, evaluation of infrastructure components, implementation of technical solutions, continuous investigation, and proactive adaptation.
Practically, the DC operation team shall investigate subjects related to power availability, cooling system capacity, network latency, and structural elements like space or raised floors in detail. Essential points are discussed below as starting points for further investigation.
Most existing data centers work with average rack densities of 3 to 6 kW per rack. However, system records must be recalled by the DC operator to identify exact power consumptions and design references. The operator shall also consider the capacity of the existing overhead power distribution system, along with an available rating of points of connection (socket, tap-off, etc.).
Typical 32A to 63A 3P/230V rated points of rack connection are available within existing data centers that follow the IEC 230/400V voltage system. Depending on the available power distribution system, rack densities from 10 to 20 kW are also possible but not in scale.
Expected rack densities for AI-ready servers are larger than 20 KW and can reach values equal to 50kW or more. The table below presents indicative rack densities based on the type of AI workload.
Data The purpose of cooling in any data center is to remove the heat produced by IT equipment inside the data hall area and maintain proper temperature and humidity conditions within the operation range of IT equipment. Most existing data centers use air cooling systems for the IT rooms, where cooled air is provided within the spaces through terminals like CRAC or CRAH units or AHU or even FAN Wall.
Air as a means of heat removal has a certain thermodynamic capacity limitation, and air-cooling systems have been proved to be a satisfactory and mature solution for rack densities up to 20 kW.
In AI clusters where the rack densities are above this value and can potentially reach figures equal to 50 or 80 kW/rack, alternative technologies are needed, with the most appropriate being liquid cooling (LC). Liquid cooling is represented by three main technologies: the Rear Door Heat Exchanger, Direct-to-Chip (DTC), and Immersive Cooling (IC). All can support extreme rack densities.
Rear-door heat exchangers are a mature technology that provides a viable solution for managing densities above 20 kW. While these technologies don’t bring liquid directly to the server, they do utilize liquid’s high thermal transfer properties and employ similar data center infrastructure as that required for direct liquid cooling.
Passive or active heat exchangers replace the rear door of the IT equipment rack with a liquid heat exchanger. With a passive design, server fans expel heated air through a liquid-filled coil mounted in place of the rack’s rear door. The coil absorbs the heat before the air passes into the data center. Active heat exchangers include fans to pull air through the coils and remove heat from even higher-density racks.
The DTC uses a liquid-cooled plate directly in touch with the server CPU/GPU and a network of micro-pipes and manifolds that circulate liquid to a Central Distribution Unit (CDU) and heat exchanger simultaneously.
The CDU is a liquid-to-liquid heat exchanger, with one side connected to the rack cooling manifolds and the other to the data center chilled water system or a refrigerant cooling system. It can be internal to each rack or a separate stand-alone unit within the data hall.
Immersive cooling (IC) is a solution in which servers are completely immersed in a dielectric liquid, and heat is directly transferred from the electronic components to the fluid. This approach takes direct advantage of the fact that liquids’ thermal conductivity and heat-carrying capacity are multiple times greater than those of air. This allows configurations where each tank can accommodate IT capacity from 150 to 600 kW over a 6 – 10 sqm footprint.

AI clusters for model training shall engage a large number of GPUs, providing separate network ports for each. Connection with high-speed network cables will allow for the complete utilization of processing speed. The operators shall coordinate with the IT development team to evaluate network cable options.
Using fiber allows larger distances between nodes and clusters, reducing the rack density with fewer servers per rack. On the other hand, in the case of copper cables, limitations on distance will force the team to stack more servers within the same racks to reduce the network latency. In this case, higher rack densities will make the system deployment more complicated and demanding for the DC infrastructure.
Except for power and cooling provisions required by DC operators for an AI-ready data center, several other points shall be equally investigated and verified that can serve or be rectified to accommodate the AI upgrade.
Racks sized for AI servers are expected to become larger in width and height to allow enough space for deep learning servers; similarly, in cases where larger PDUs are designed for increased power rating and space for liquid cooling, the manifold will push for deeper racks. Also, the operators shall check the durability of AI-specified racks as more heavy gear is expected to be installed.
For DCs with raised floors, the operators shall carefully evaluate the floor-concentrated design load and wheel rolling load. AI racks will become heavier than normal density racks, and special consideration should be given.
Main runs of chilled water pipes for connection with DTC liquid-cooled racks or IC tanks are not preferred for most operators to be from above. The DC operation team shall verify whether the existing chilled water system can be used or identify new routes. In the case of raised floor existence, normally, the pipe runs will be underneath, but for facilities without, different options shall be explored through adjacent corridors or by providing trenches on the floor.
Data center operators shall investigate their existing and future market needs in coordination with their business targets and budget allocations. The creation of a medium—and long-term plan related to IT capacity management and rack density distribution will allow them to make critical decisions related to all technical subjects analyzed above. Continuous communication with the market, evaluation of technology trends, and cooperation with existing and future clients are key components of strategy development.
In many existing data centers where complete new design and development are not part of business planning, hybrid-type data centers are appropriate for short- to medium-term development. A hybrid DC shall continue to operate all existing facilities, including IT racks and air cooling, but simultaneously will allocate power and space for a small, dedicated AI cluster with increased power supply and liquid cooling following client needs.
Hybrid-type solutions create concerns for Tier-certified DCs and the impact on their certification, although discussions for future DC facilities with multiple Tier certificates may arise as a solution.
Similarly, the absence of international standards for certification of liquid cooling systems is a subject of concern, and further investigation from the DC community is required, as most of the market-proposed solutions are developed and tested only by the vendors. Institutional certifications for AI hardware and liquid cooling solutions have become a necessity, along with the involvement of international facility certification standards like Uptime Institute Tier rating.
Furthermore, the evolution of new technologies, like Tensor Processing Units (TPU), is subject to challenges from GPUs and steers the market even further. Technological trends and different approaches in terms of hybrid cloud models will impact more.
Developers tend to use ‘public data’ to develop a foundational model on the cloud and then augment and make it business-specific using private data in their own computing facilities to maintain control of their data. Then, the model will be deployed, and all the inferencing will happen on the edge. This workflow model leaves colocation DCs out of the loop for much of the workload.
The future is expected to be very interesting, and the evolution of AI as a service within data centers is currently knocking on the door for facility managers.